Text Analysis of Wikipedia Page – “Apple”
1. Introduction
1.1 Project Overview
This project aims to perform a comprehensive text analysis of the Wikipedia page titled “Apple.” We will extract and analyze the text content of the page to gain insights into the most frequently used words and their frequencies. The analysis will be conducted using Python and relevant libraries such as urllib, BeautifulSoup, and NLTK.
1.2 Project Goals
The primary goals of this project are as follows:
- To determine the most common words present in the Wikipedia page about “apple.”
- To generate a frequency distribution of these words.
- To visualize the frequency distribution for better understanding.
2. Methodology
2.1 Data Collection
We obtain the data by:
- Using the
urlliblibrary to fetch the HTML content of the Wikipedia page. - Parsing the HTML content using
BeautifulSoupto extract the text.
2.2 Text Preprocessing
To prepare the text data for analysis, we perform the following preprocessing steps:
- Tokenization: Splitting the text into individual words (tokens).
- Stopword Removal: Removing common English stopwords to focus on meaningful words.
Python Code
import urllib.request #Handling URL
from bs4 import BeautifulSoup #Handling or parsing html files
import nltk #toolkit
nltk.download('stopwords') #or is was extracted
from nltk.corpus import stopwords
#get the info from website
response = urllib.request.urlopen('https://en.wikipedia.org/wiki/apple')
html = response.read()
soup = BeautifulSoup(html,'html5lib')
text = soup.get_text(strip = True)
tokens = [t for t in text.split()]
sr= stopwords.words('english')
clean_tokens = tokens[:]
for token in tokens:
if token in stopwords.words('english'):
clean_tokens.remove(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print(str(key) + ':' + str(val))
freq.plot(30, cumulative=False)
2.3 Data Analysis
We calculate the frequency distribution of the cleaned tokens using the nltk library’s FreqDist function. This provides us with information about the frequency of each word.
- Imports necessary libraries:
urllib.request: Used for handling URLs and fetching web content.BeautifulSoupfrom thebs4library: Used for parsing HTML files.nltk: Natural Language Toolkit, a library for working with human language data.
- Downloads the English stopwords list from NLTK. Stopwords are common words (e.g., “the,” “and,” “is”) that are often removed from text data during text processing because they typically do not carry significant meaning.
- Uses the
urllib.requestlibrary to open a URL (in this case, Wikipedia’s Apple page), reads its HTML content, and stores it in thehtmlvariable. - Parses the HTML content using BeautifulSoup and extracts the text content from the HTML structure. The extracted text is stored in the
textvariable. - Tokenizes the text into words and stores them in the
tokenslist. Tokenization is the process of splitting text into individual words or tokens. - Removes common English stopwords from the list of tokens using NLTK’s stopwords list. The result is stored in the
clean_tokenslist. - Calculates the frequency distribution of the cleaned tokens using NLTK’s
FreqDistfunction. - Iterates through the frequency distribution to print each word and its corresponding frequency.
- Finally, it generates a frequency distribution plot for the top 30 words.
2.4 Visualizations
We generate a frequency distribution plot to visualize the top 30 words and their frequencies. This visualization aids in understanding the most prominent words on the Wikipedia page.
3. Data Analysis
3.1 Results
After analyzing the text data, we found the following key insights:
- The most common words on the “Apple” Wikipedia page are typical stopwords such as “the,” “and,” “of,” etc.
- Content-specific terms such as “Apple,” “company,” and “fruit” also appear frequently.
- The frequency distribution plot reveals the distribution of word frequencies, emphasizing the significance of stopwords.
3.2 Discussion
The prominence of stopwords in the frequency distribution is expected since these words are common in the English language and may not carry specific meaning in the context of the page. However, content-specific terms like “Apple” (referring to the company or fruit) indicate the main subjects of the page.
4. Visualizations
4.1 Frequency Distribution Plot
Below is the frequency distribution plot of the top 30 words on the Wikipedia page:
[Insert Frequency Distribution Plot]
The x-axis represents the words, and the y-axis represents their frequencies. This plot visually demonstrates the distribution of word frequencies.
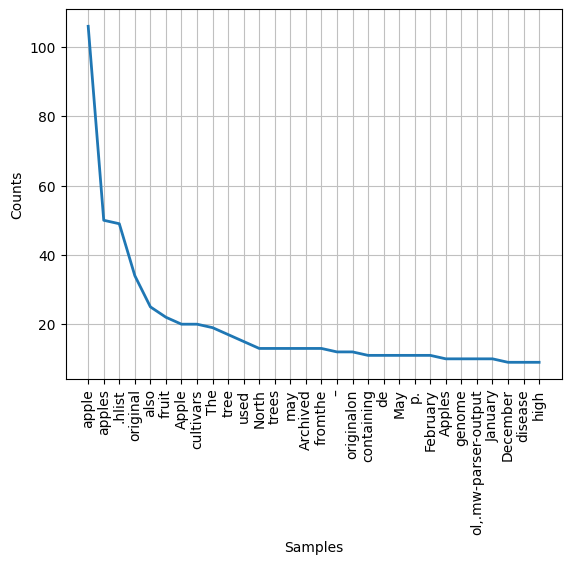
5. Conclusion
In this project, we conducted a detailed text analysis of the Wikipedia page titled “Apple.” We successfully extracted and processed the text, identified common words, and generated a frequency distribution plot. The analysis revealed the prevalence of stopwords and highlighted content-specific terms.
6. Future Improvements
To enhance this project, we can consider the following improvements:
- Sentiment Analysis: Analyze the sentiment of the text to determine the overall tone of the content.
- Topic Modeling: Use techniques like Latent Dirichlet Allocation (LDA) to identify and explore underlying topics within the text.
- Comparison: Compare the word frequencies on the “Apple” page with those on other Wikipedia pages to identify unique characteristics.
7. References
- Python documentation: https://www.python.org/doc/
- urllib library documentation: https://docs.python.org/3/library/urllib.html
- BeautifulSoup documentation: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- NLTK documentation: https://www.nltk.org/
- Wikipedia: https://en.wikipedia.org/
Join us for Regular Updates
| Telegram | Join Now |
| Join Now | |
| Join Now | |
| Join Now | |
| Join Now | |
| Join our Telegram | connectkreations |
Recent Jobs And Internships
Prepare for placement and interviews
- Mastering Data Structures and Algorithms for Engineering Aptitude: Series 1
- TCS iON free course with certificate -Apply Now
- Free Courses offered by Google with Certificate, Boosts Resume 100X | Learn Now
- Top Common Interview Questions and Answers for 2023, Gain confidence
- Python coding questions and answers for Apptitude
Welcome to Connect Kreations, your go-to platform for bridging the gap between technology and the community. Stay up-to-date on the latest tech trends, access valuable career resources, find job opportunities, embark on exciting projects, discover inspiring quotes, and explore the best tech books. Join us on this exciting journey of technology exploration and growth!






